Graphcore – GPUに替わる新たなAI(人工知能)用プロセッサIPUで新領域を切り開く英国のスタートアップ

AI(人工知能)用のプロセッサとしてGPU(グラフィックス・プロセッシング・ユニット)が適していると言われてからすでに10年近い年月が流れている。グラフィックスに必要な行列の積和演算が並列処理により高速に実行できるというGPUの特徴が、機械学習やニューラルネットワークの計算にも適しているということで注目され、GPUが今のところAI(人工知能)用のプロセッサとして先行している。特に、2012年に、GPUを使ったAlexNetが画像認識のコンペティション(ImageNet)で圧勝してから、ディープラーニングのブームが一気に加速した。
GPUはそもそもグラフィックス用に設計されたものであるから、2次元、3次元など低次の行列演算には適している。AI(人工知能)の画像認識への応用の場合、CNN(畳み込みニューラルネットワーク)による画像フィルタの計算が主になるので、特に入り口に近い層ではGPUの得意分野を活かした高速な演算が可能である。しかし、より汎用のAI(人工知能)への応用には必ずしも適しているとは言えない。

英国ロンドンの西、約200kmの都市、ブリストルに本拠を置くスタートアップ「グラフコア (Graphcore) 社は、GPUの次に来るAI(人工知能)用のプロセッサの一つの有力候補であるIPU(インテリジェント・プロセッシング・ユニット)を開発している。この会社は、2016年にNigel Toon (CEO)とSimon Knowles (CTO) によって設立され、これまでにBMW、マイクロソフト、サムスン、ボッシュ、デルなどから多くの投資を集め、時価総額は$1.95 billion と言われているユニコーン企業である。従業員は2020年7月現在300人を超え、この1年間で約2倍になっている。
IPUを一言で言うならば「グラフ計算マシン」であり、対比させていうとCPUはスカラー計算マシン、GPUはベクター計算マシンということになろう。「グラフ」とは、ノード(節点、頂点)の集合とエッジ(枝、辺)の集合で構成される構造のことで、ニューラルネットワーク的には、ニューロンとシナプスによって構成される構造に相当すると言っても良い。IPUのノードはローカルメモリを持った演算ユニット(プロセッサコアと呼ぶ)であり、エッジは方向性を持つ有向グラフである。ディープニューラルネットワーク等による汎用のインテリジェンスマシンではグラフ演算が主体になるので、それをターゲットにしたプロセッサには優位性があると考えられる。

グラフコアは2018年に最初のIPU製品を搭載したPCIeのアクセラレータボードを発売。そして、今回2020年7月に 7nm のプロセスを用いた新たなIPU「Colossus Mk2 GC200」、およびそれを1Uのシャーシに4個搭載し、1PFLOPS(ペタフロップス)のAI計算を提供するインテリジェントマシンIPU-M2000を発表した。IPU-M2000は、スケーラブルな設計となっており、IPU-Fabricという高速・低遅延の通信技術を用いることで1台から数千台まで、シームレスにシステムを組むことができる。製品としては、IPU-POD64というIPU-M2000を16台ラックマウントしたクラスタシステムも販売している。
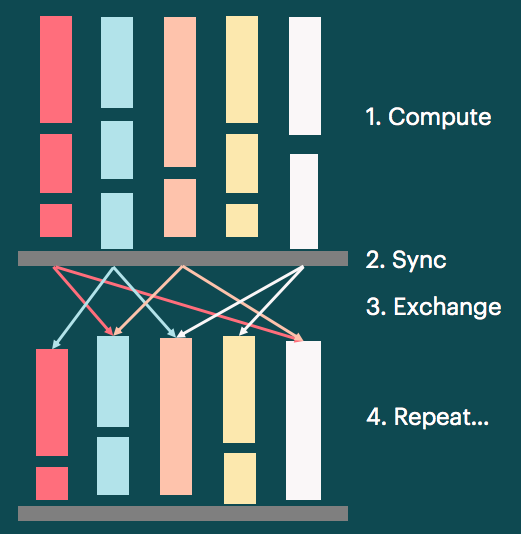
超並列マシンであるIPUの設計に関しては、いくつかのコンセプトが実装されている。バルク同期並列 (BSP) は、各プロセッサコアはローカルメモリを用いて計算を行い、全部のユニットで計算が終了した後、同期してユニット間通信を行うという考え方であり、それ自体は新しいものではない。IPUではグラフのコネクションは、スパースであり静的であるという前提に立っており、BSPにおける演算資源の割当てや同期通信のスケジューリングは、コンパイラがあらかじめ決定することができる。これにより、デッドロックが生じない設計になっている。
共有メモリではなく、プロセッサコアごとにローカルメモリを持たせたのには、発熱問題へのソリューションの意味もある。微細化により演算部の集積度を上げていくと問題になるのがパワー密度で、熱の問題のためにクロック周波数が上げられなかったり、あまり稼働率の高くない回路(ダークシリコン)を入れたり、本来あるべきプロセッサの姿から逸脱する設計をせざるを得ないという状況が生じている。それに対して、ローカルメモリを入れてパワー密度を下げるというのがIPUのとった戦略である。
グラフコアのウェブサイトに各種ベンチマークの資料が載っており、全ての分野においてGPUを上回る性能であることが示されている。
IPUのソフトウェアとしては「Poplar SDK」が利用できる。これは既存の機械学習のフレームワークとの互換性を保ちながら、IPUの性能を最大限に活用できるアーキテクチャとなっている。利用できるフレームワークとしては、現在、TensorFlow, ONNX, PyTorchなどである。また、PythonおよびC++で直接IPUプログラミングを行うことも可能である。
本記事では、グラフコアのIPUについて、表層的なレベルでの紹介を行った。今後IPUがGPUに替わるAI(人工知能)用のプロセッサとしての揺るぎない地位を獲得するのか、予断を許さないところであり、引き続き注目すべき技術である。